分库分表原理
分库分表目的
分库分表目的:解决高并发,和数据量大的问题。
- 1、高并发情况下,会造成IO读写频繁,自然就会造成读写缓慢,甚至是宕机。一般单库不要超过2k并发
- 2、数据量大的问题,主要由于底层索引实现导致,MySQL的索引实现为B+TREE,数据量大,会导致索引树十分庞大,造成查询缓慢,其次,innodb的最大存储限制64TB。
要解决上述问题。最常见做法,就是分库分表。
分库分表的目的,是将一个表拆成N个表,就是让每个表的数据星控制在一定范围内,保证SQL的性能。一个表数据建议不要超过500W。
分库分表的类别
- 水平就是切割数据,垂直就是切割结构
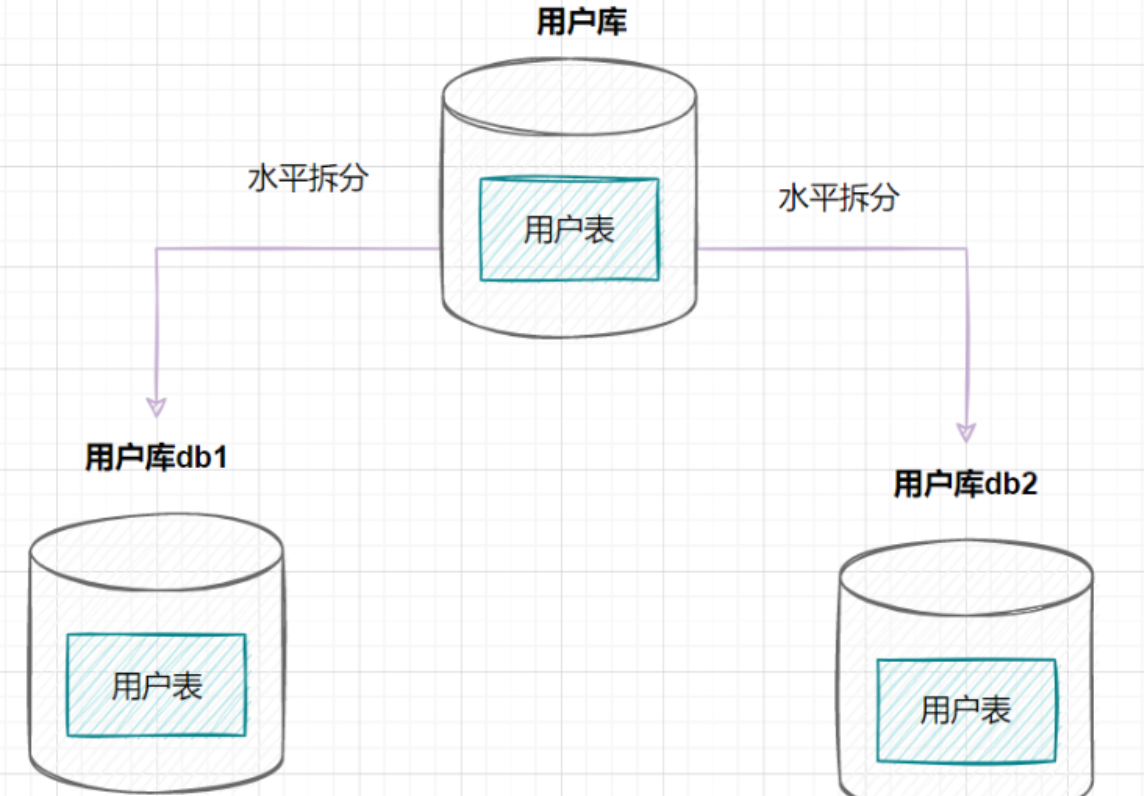
水平分库
水平分库是指,将表的数据量切分到不同的数据库服务器上,每个服务器具有相同的库和表,只是表中的数据集合不一样。它可以有效的缓解单机单库的性能瓶颈和压力
- 每个库的结构都一样
- 每个库的数据都不一样,没有交集
- 所有库的并集是全量数据
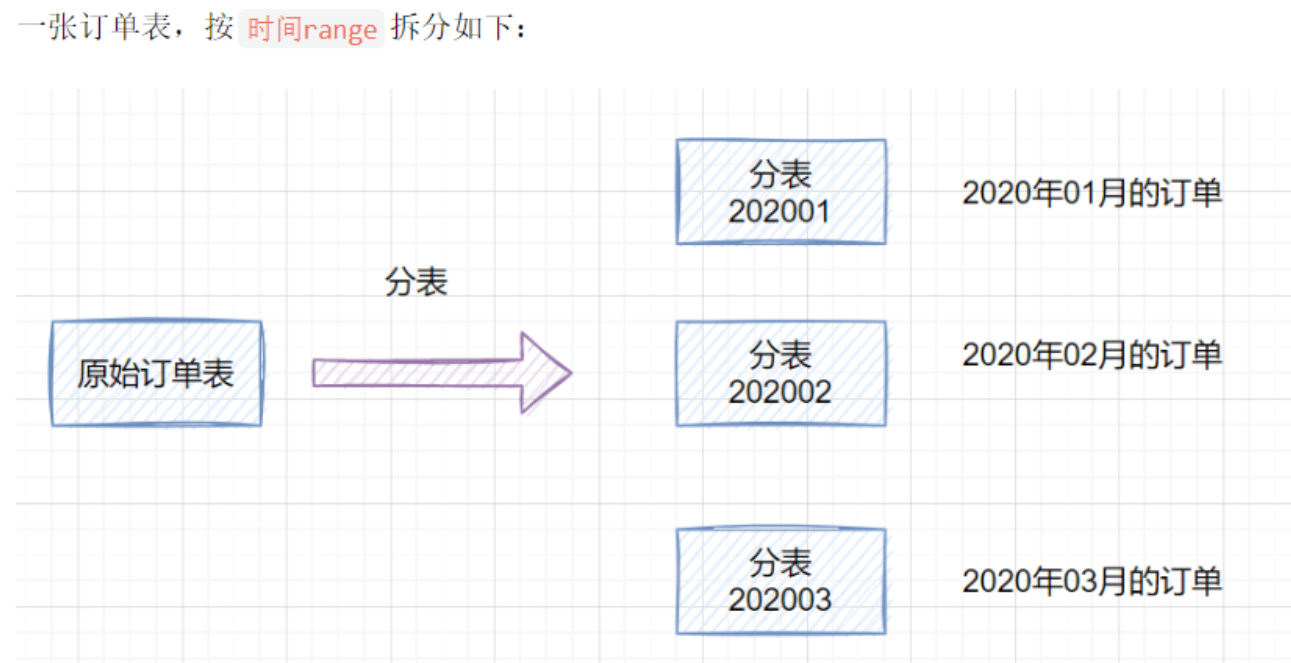
水平分表
如果一个表的数据量太大,可以按照某种规则(如hash取模、range),把数据切分到多张表去。
- 每个表的结构都一样
- 每个表的数据都不一样,没有交集
- 所有表的并集是全量数据
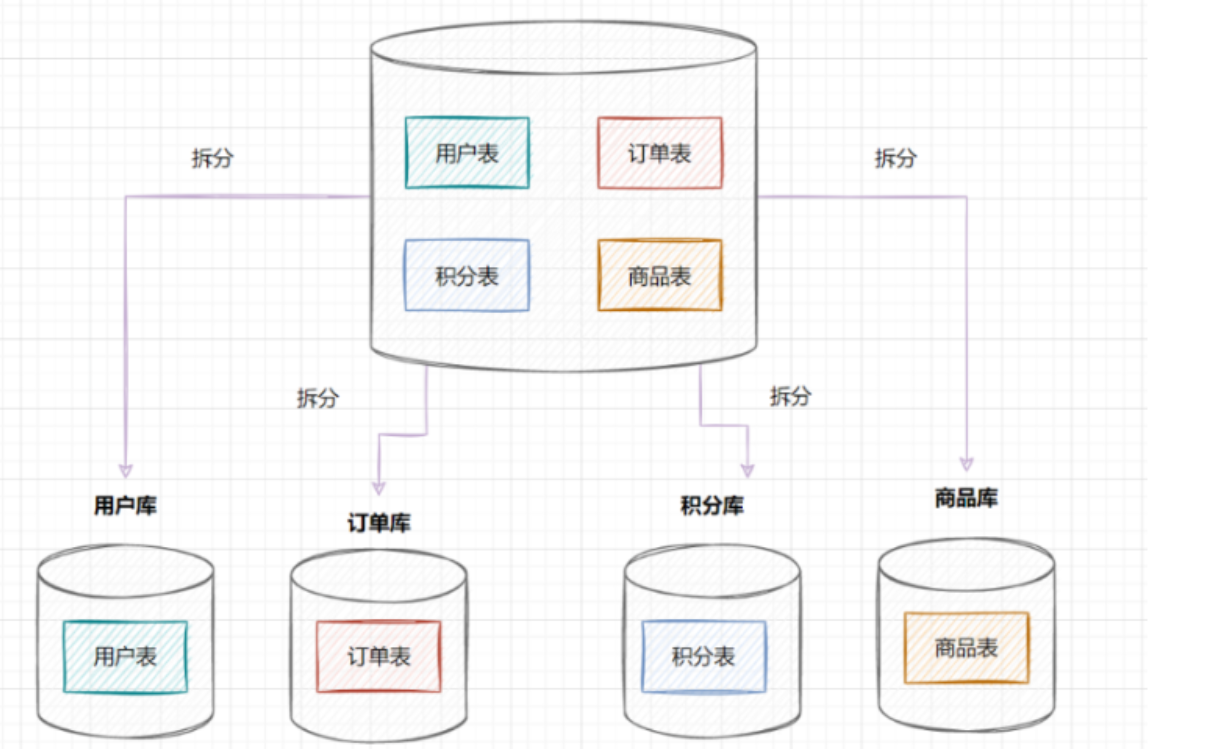
垂直分库
垂直分库,将原来一个单数据库的压力分担到不同的数据库,可以很好应对高并发场景。
- 每个库的结构都不一样
- 每个库的数据也不一样,没有交集
- 所有库的并集是全量数据
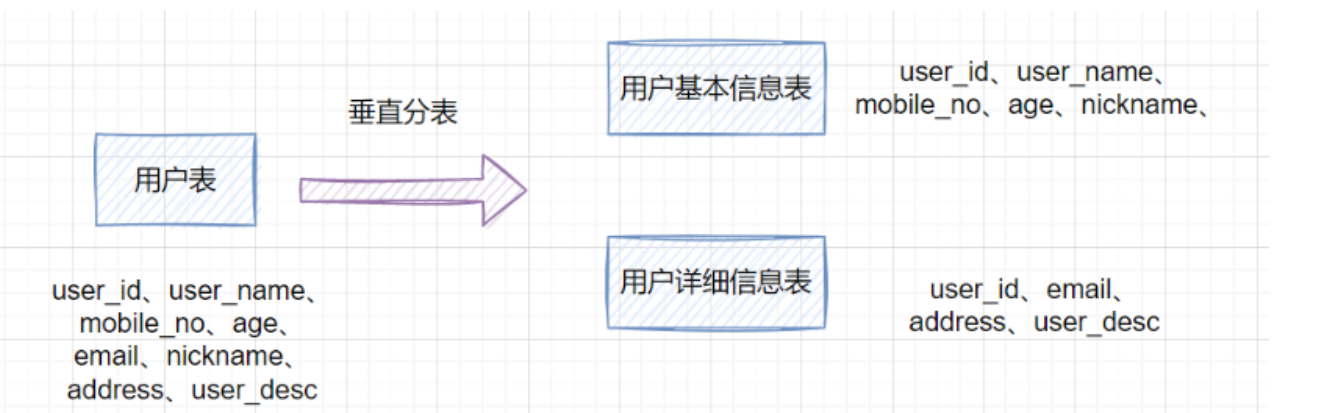
垂直分表
如果一个单表包含了几十列甚至上百列,管理起来很混乱,每次都select *的话,还占用IO资源。这时候,我们可以将一些不常用的、数据较大或者长度较长的列拆分到另外一张表。
- 每个表的结构都不一样
- 每个表的数据也不一样,一般来说,每个表的字段至少有一列交集,一般是主键,用于关联数据
- 所有表的并集是全量数据
分库分表的策略
分库分表策略一般有几种,使用与不同的场景:
range范围hash取模range+hash取模混合
range范围
range,即范围策略划分表。比如我们可以将表的主键,按照从0-1000万的划分为一个表,1000-2000万划分到另外一个表
优点
这种方案有利于扩容,不需要数据迁移。假设数据量增加到5千万,我们只需要水平增加一张表就好啦,之前0~4000万的数据,不需要迁移
缺点
这种方案会有热点问题,因为订单id是一直在增大的,也就是说最近一段时间都是汇聚在一张表里面的。比如最近一个月的订单都在1000万~2000万之间,平时用户一般都查最近一个月的订单比较多,请求都打到order_1表啦,这就导致数据热点问题
hash取模
优点
hash取模的方式,不会存在明显的热点问题
缺点
如果一开始按照hash取模分成4个表了,未来某个时候,表数据量又到瓶颈了,需要扩容,这就比较棘手了。比如你从4张表,又扩容成8张表,那之前id=5的数据是在(5%4=1,即table_1),现在应该放到(5%8=5,即table_5),也就是说历史数据要做迁移了
range+hash取模混合
既然range存在热点数据问题,hash取模扩容迁移数据比较困难,我们可以综合两种方案一起,取之之长,弃之之短。
比较简单的做法就是,在拆分库的时候,我们可以先用range范围方案,比如订单id在0-4000万的区间,划分为订单库1;id在4000-8000万的数据,划分到订单库2,将来要扩容时,id在8000-1.2亿的数据,划分到订单库3。然后订单库内,再用hash取模的策略,把不同订单划分到不同的表
逻辑表
逻辑表是指:水平拆分的数据库或者数据表的相同路基和数据结构表的总称。比如用户数据根据 userId%2拆分为2个表,分别是: ksd_user0和ksd_user1。他们的逻辑表名是: ksd_user。
在shardingjdbc中的定义方式如下
spring:
shardingsphere:
sharding:
tables:
#t_user 逻辑表名
t_user:
数据节点actual-data-nodes
spring:
shardingsphere:
sharding:
tables:
#ksd_user 逻辑表名
ksd_user:
#数据节点:多数据源$->{0..N}.逻辑表名$->{0..N}相同表
actual-data-nodes: ds$->{0..2}.ksd_user$->{0..1}
#数据节点:多数据源$->{0..N}.逻辑表名$->{0..N}不相同表
actual-data-nodes: ds0.ksd_user$->{0..1},ds1.ksd_user$->{2..4}
#指定单数据源的配置方式
actual-data-nodes: ds0.ksd_user$->{0..4}
# 全部手动指定
actual-data-nodes: ds0.ksd_user0,ds1.ksd_user0,ds0.ksd_user1,ds1.ksd_user1
分片策略
不停机分库分表数据迁移
一般数据库的拆分也是有一个过程的,一开始是单表,后面慢慢拆成多表。那么如何平滑的从MySQL单表过度到MySQL的分库分表架构?
- 1、利用
mysql+canal做增量数据同步,利用分库分表中间件,将数据路由到对应的新表中。 - 2、利用分库分表中间件,全量数据导入到对应的新表中。
- 3、通过单表数据和分库分表数据两两比较,更新不匹配的数据到新表中。
- 4、数据稳定后,将单表的配置切换到分库分表配置上。